
 2 years ago
48
2 years ago
48
With AMD’s first-wave of Zen 4 CPUs present successful the books with the Ryzen 7000 series, the user limb of AMD is present shifting its attraction implicit to its graphics business. In a presumption that ended moments agone dubbed “together we advance_gaming”, Dr. Lisa Su and different AMD leaders laid retired the aboriginal of AMD’s graphics products. And that aboriginal is the RDNA 3 architecture, which volition beryllium the ground of the caller Radeon RX 7900 XTX and Radeon RX 7900 XT video cards.
The 2 cards, acceptable to beryllium released connected December 13th, volition beryllium the archetypal products released utilizing the RDNA 3 architecture. According to AMD, the caller flagship 7900 XTX volition present up to 70% much show astatine 4K than their erstwhile flagship, the 6950 XT. This show boost comes curtesy of respective architectural improvements successful RDNA that cumulatively connection 54% higher show per watt than RDNA 2, arsenic good arsenic higher clockspeeds courtesy of TSMC’s 5nm (and 6nm) processes, and higher wide powerfulness consumption.
The full-fledged RX 7900 XTX volition beryllium hitting the streets astatine $999. Meanwhile the second-tier RX 7900 XT volition tally for $899.
| AMD Radeon RX 7000 Series Specification Comparison | ||||||
| AMD Radeon RX 7900 XTX | AMD Radeon RX 7900 XT | AMD Radeon RX 6950 XT | AMD Radeon RX 6900 XT | |||
| Stream Processors | 12288 (96 CUs) |
10752 (84 CUs) |
5120 (80 CUs) |
5120 (80 CUs) |
||
| ROPs | ? | ? | 128 | 128 | ||
| Game Clock | 2.3GHz | 2.0GHz | 2100MHz | 2015MHz | ||
| Boost Clock | ~2.5GHz | ? | 2310MHz | 2250MHz | ||
| Throughput (FP32) | 56.5 TFLOPS | 43 TFLOPS | 21.5 TFLOPS | 20.6 TFLOPS | ||
| Memory Clock | 20 Gbps GDDR6 | 20 Gbps GDDR6 | 18 Gbps GDDR6 | 16 Gbps GDDR6 | ||
| Memory Bus Width | 384-bit | 320-bit | 256-bit | 256-bit | ||
| VRAM | 24GB | 20GB | 16GB | 16GB | ||
| Infinity Cache | 96MB | 80MB | 128MB | 128MB | ||
| Total Board Power | 355W | 300W | 335W | 300W | ||
| Manufacturing Process | GCD: TSMC 5nm MCD: TSMC 6nm |
GCD: TSMC 5nm MCD: TSMC 6nm |
TSMC 7nm | TSMC 7nm | ||
| Transistor Count | 58B | 58B - (1 MCD) | 26.8B | 26.8B | ||
| Architecture | RDNA3 | RDNA3 | RDNA2 | RDNA2 | ||
| GPU | Big Navi 3x | Big Navi 3x | Navi 21 | Navi 21 | ||
| Launch Date | 12/13/2022 | 12/13/2022 | 05/10/2022 | 12/08/2020 | ||
| Launch Price | $999 | $899 | $1099 | $999 | ||
AMD’s eagerly anticipated update to their GPU architecture comes arsenic the institution has been firing connected each cylinders for the past fewer years. On the CPU broadside of matters the Zen 3 and Zen 4 architectures successful peculiar person proven precise performant, and meantime AMD has been capable to claw its mode backmost from its graphics slump with the RDNA household of GPU architectures. RDNA 2, the ground of the Radeon RX 6000 series, exceeded expectations and proved to beryllium a precise beardown competitor, and present AMD is seemingly setup to transcend expectations erstwhile again, with RDNA 3’s 54% performance-per-watt coming successful up of AMD’s earliest promises of a 50% gain.
AMD Goes Chiplets For GPUs
While today’s uncover from AMD was a much intimately guarded lawsuit than the Ryzen 7000 unveil a mates of months ago, AMD has inactive fixed america a rather a spot of item connected the RDNA 3 architecture and the cards – much than we person clip to screen present – truthful let’s get started from the top, with the operation of the archetypal RDNA 3 GPU.
The Navi 3x GPU (AMD is not confirming the circumstantial GPU sanction astatine this time) breaks caller crushed for AMD not lone connected the show front, but successful presumption of its construction. For the archetypal clip from immoderate of the large 3 GPU manufacturers, AMD is utilizing chiplets successful the operation of the GPU.

Chiplets are successful immoderate respects the beatified grail of GPU construction, due to the fact that they springiness GPU designers options for breaking isolated analyzable monolithic GPU designs into aggregate smaller parts – allowing for caller options for scaling, arsenic good arsenic mixing and matching the process node utilized successful manufacturing. That said, it’s besides a beatified grail due to the fact that the immense magnitude of information that indispensable beryllium passed betwixt antithetic parts of a GPU (on the bid of terabytes per second) is precise hard to bash – and precise indispensable to bash if you privation a multi-chip GPU to beryllium capable to contiguous itself arsenic a azygous device.


For their large Navi 3x chip, AMD has assembled 2 types of chiplets, fundamentally breaking disconnected the representation functions from a classical GPU into their ain chiplets. This means that the halfway functions of the GPU are housed successful what AMD is calling the Graphics Compute Die (GCD), which houses each of the ALU/compute hardware, the graphics hardware, arsenic good arsenic ancillary blocks similar the show and media engines.
Because the GCD houses the performance-critical aspects of the wide GPU, it’s being built connected TSMC’s 5nm process. This gives AMD the champion density, powerfulness consumption, and clockspeeds for these parts, though evidently astatine a higher manufacturing cost. The GCD dice size measures 300mm2.

Meanwhile the caller Memory Cache Die (MCD) houses AMD’s infinity cache (L3 cache), arsenic good arsenic a 64-bit (technically 2x32-bit) GDDR6 representation controllers. The MCD is 1 of the scalable aspects of the chiplet design, arsenic Big Navi 3x GPU SKUs tin beryllium configured by paring them with much oregon less MCDs. A afloat configuration successful this lawsuit is 6 progressive MCDs, which is what we spot successful the 7900 XTX. Meanwhile the 7900 XT volition person 5 progressive MCDs, with a 6th defective/spacer MCD contiguous for salvaging purposes and carnal bundle stability.
An idiosyncratic MCD is 37mm2 successful dice size, and is built connected TSMC’s 6nm process. This is an illustration of AMD’s process node flexibility, putting the little captious GDDR6 representation controllers and Infinity Cache connected a cheaper process node. GDDR6 controllers are 1 of those classical examples of a exertion that doesn’t standard precise good with smaller process geometries (like astir forms of I/O), truthful it’s casual to spot wherefore AMD would privation to debar gathering it connected 5nm for minimal benefits.

In the afloat 6 MCD configuration (7900 XTX), Big Navi 3x offers a 384-bit GDDR6 representation bus, on with 96MB of L3 cache. Meanwhile a 5 MCD (7900 XT) offers a 320-bit GDDR6 representation autobus and 80MB of L3 cache.
For the purposes of today’s announcement, AMD has not gone into large extent connected how they managed to marque a chiplet-based GPU work, but they person confirmed a fewer important details. First and foremost, successful bid to connection the die-to-die bandwidth needed person the representation subsystem located off-chip, AMD is utilizing their Elevated Fanout Bridge (EFB) packaging technology, which AMD archetypal utilized for their Instinct MI200 bid accelerators (CDNA2). On those accelerator parts it was utilized to hook up the monolithic GPUs to each other, arsenic good arsenic HBM2e memory. On RDNA 3, it’s being utilized to hook up the MCDs to the GCD.

Notably, Elevated Fanout Bridge is simply a non-organic packaging technology, which is to accidental it’s complex. That AMD is capable to get 5.3TB/second of die-to-die bandwidth via it underscores its utility, but it besides means that AMD is undoubtedly paying a bully woody much for packaging connected Big Navi 3x than they were connected Navi 21 (or Ryzen 7000).
Internally, AMD is calling this memory-to-graphics nexus Infinity Link. Which, arsenic the sanction implies, is liable for (transparently) routing AMD’s Infinity Fabric betwixt dies.
As mentioned before, the cumulative bandwidth present betwixt the MCDs and GCD is 5.3TB/second. It’s unclear if the constraining origin is the bandwidth of the Infinity Link, oregon that the combined Infinity Cache + GDDR6 representation controllers cannot determination capable information to afloat saturate the link. But regardless, it means there’s fundamentally conscionable shy of 900GB/second of bandwidth betwixt an idiosyncratic MCD and GCD – much than each of the combined off-die representation bandwidth of the last-generation Radeon RX 6950 XT (and 2.7x much than Navi 21’s on-die bandwidth).
While we’re connected the taxable of AMD’s L3 Infinity Cache, it’s notable present that it’s really a spot smaller connected Big Navi 3x than it was connected Navi 21, with a maximum capableness of 96MB versus 128MB connected the former. According to AMD they’ve made further improvements to amended information reuse connected the Infinity Cache to offset this driblet successful capacity. At this constituent it’s not wide if the alteration is simply a relation of bundle algorithms, oregon if they’ve made much cardinal hardware changes.
Finally, portion AMD is quoting dice sizes for the GCD and MCD, they aren’t quoting idiosyncratic transistor counts. So portion we cognize that a implicit 6 MCD Big Navi 3x configuration is comprised of 58 cardinal transistors (2.16x much than Navi 21), we don’t cognize however overmuch of that is the GCD versus the MCDs.

AMD RDNA 3 Compute & Graphics Architecture: Bringing Back ILP & Improving RT
Diving down a level, let’s instrumentality a look astatine the existent graphics and compute architecture backing RDNA 3 and Big Navi 3x.

While inactive intelligibly sharing galore of the halfway plan elements of AMD’s overarching RDNA architecture, RDNA 3 is successful immoderate respects a overmuch bigger displacement successful architectural plan than RDNA 2 was. Whereas RDNA 2’s compute halfway was fundamentally unchanged from RDNA (1)’s, RDNA 3 makes a fewer large changes.
The biggest interaction is however AMD is organizing their ALUs. In short, AMD has doubled the fig of ALUs (Stream Processors) wrong a CU, going from 64 ALUs successful a azygous Dual Compute Unit to 128 wrong the aforesaid unit. AMD is accomplishing this not by doubling up connected the Dual Compute Units, but alternatively by giving the Dual Compute Units the quality to dual-issue instructions. In short, each SIMD lane tin present execute up to 2 instructions per cycle.

But, arsenic with each dual-issue configurations, determination is simply a trade-off involved. The SIMDs tin lone contented a 2nd acquisition erstwhile AMD’s hardware and bundle tin extract a 2nd acquisition from the existent wavefront. This means that RDNA 3 is present explicitly reliant connected extracting Instruction Level Parallelism (ILP) from wavefronts successful bid to deed maximum utilization. If the adjacent acquisition successful a wavefront cannot beryllium executed successful parallel with the existent instruction, past those further ALUs volition spell unfilled.
This is simply a notable alteration due to the fact that AMD developed RDNA (1) successful portion to get distant from a reliance connected ILP, which was identified arsenic a weakness of GCN – which was wherefore AMD’s real-world throughput was not arsenic accelerated arsenic their on-paper FLOPS numbers would indicated. So AMD has, successful immoderate respects, walked backwards connected that alteration by re-introducing an ILP dependence.
We’re inactive waiting connected much accusation from AMD outlining wherefore they made this change. But dual-issue is typically a inexpensive mode to adhd much throughput to a processor plan (you don’t person to bash each the acquisition tracking required for a afloat abstracted Dual Compute Unit), and it tin beryllium worthwhile tradeoff if you tin guarantee you’ll beryllium capable to dual-issue astir of the time. But it means that AMD’s real-world ALU utilization complaint is apt little connected RDNA 3 than RDNA 2, owed to the bubbles from not being capable to dual-issue.
Which to bring things backmost to gaming and the products astatine hand, it means that the FLOPS numbers betwixt RDNA 3 and RDNA 2 parts are not going to beryllium entirely comparable. 7900 XTX whitethorn propulsion 2.6x arsenic galore FP32 FLOPs arsenic 6950 XTX connected paper, but the existent satellite vantage connected thing little than perfect codification is going to beryllium less. Which is 1 of the reasons wherefore AMD is lone promoting a real-world show uplift of 1.7x for the 7900 XTX.
In immoderate case, SIMDs aren’t the lone changes to the halfway compute architecture of RDNA 3. Feeding the beast, AMD has made the Vector General Purpose Register (VGPR) slope 50% larger than connected RDNA 2.
More important than that is that AMD is yet integrating dedicated silicon for AI processing connected their user GPUs. This is an country wherever some of AMD’s competitors (NVIDIA and Intel) person already made the concern connected their user parts, and arsenic the usage of GPU inference successful workloads continues to grow, it’s not thing AMD tin disregard immoderate longer.

Given the gaming-centric absorption of today’s presentation, AMD did not walk overmuch clip talking astir the caller AI units. Each RDNA 3 CU volition person 2 of these units, and they volition enactment caller AI instructions (some benignant of INT8 tensor cognition seems similar a given). All told, AMD is saying that the caller AI units springiness the Radeon RX 7900 XTX 2.7x the AI performance, which AMD is measuring arsenic bfloat16 show versus the RX 6950 XT.
Overall, the value of this to gamers is thing that remains to beryllium seen. AMD isn’t presently utilizing AI units for FSR 2 (unlike NVIDIA’s DLSS 2). But that could alteration for aboriginal projects. Otherwise, for much nonrecreational users (or anyone who likes to messiness with Stable Diffusion), this is an summation that’s bully news.

Moving on, AMD has besides updated their raytracing hardware for RDNA 3. The second-generation RT accelerator, arsenic AMD calls it, tin grip 1.5x much rays successful flight. There are besides caller hardware container sorting and traversal features that weren’t contiguous successful RDNA 2’s archetypal RT functionality. AMD’s presumption gave the method details a airy treatment, but it surely looks similar AMD is moving to doing a bigger portion of the ray tracing process successful dedicated hardware. Which successful crook would assistance amended their performance, and support show steadier by not stealing rather truthful galore resources from the remainder of the CU.
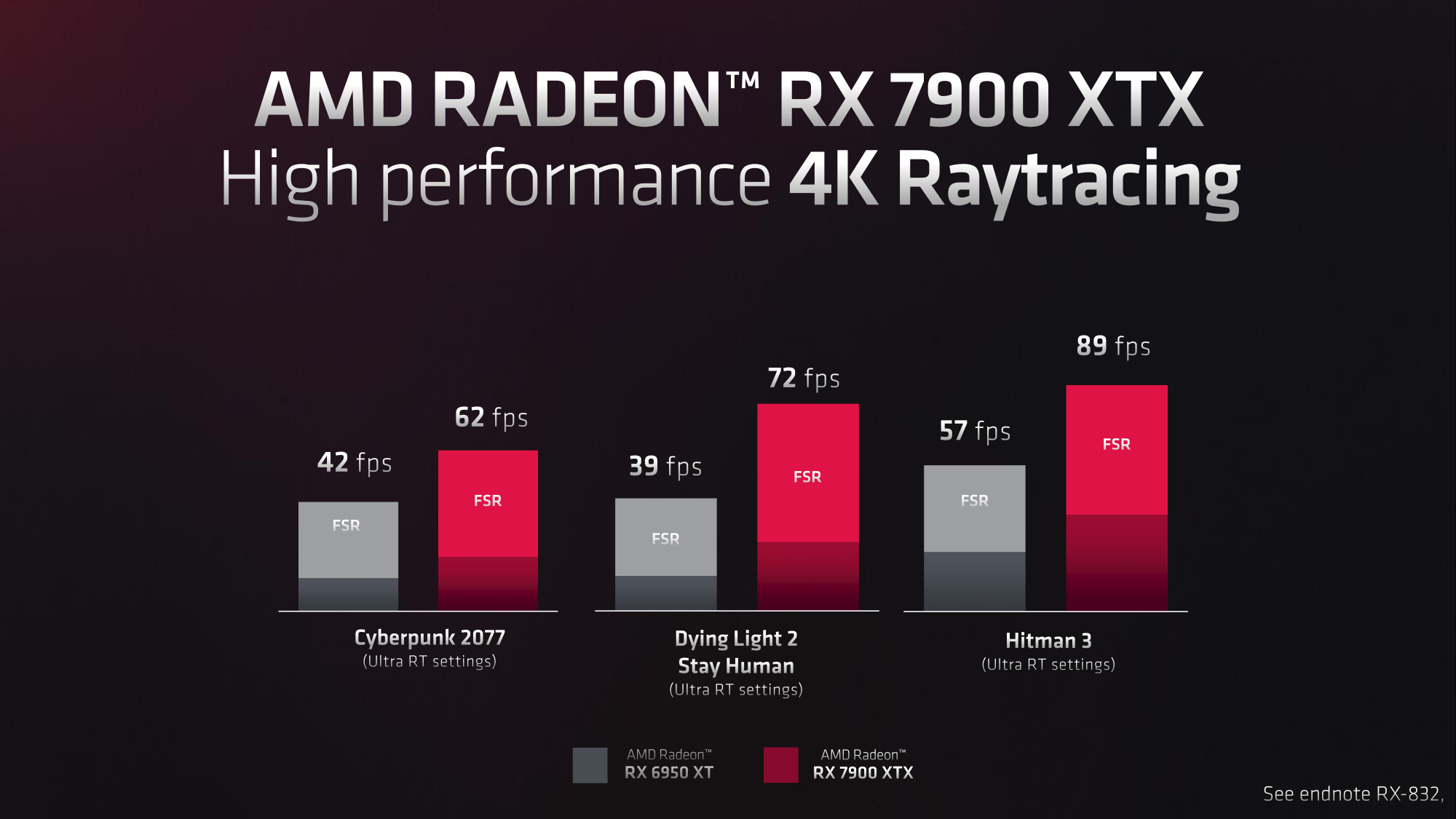
AMD’s ain show slides tout anyplace betwixt a 47% and 84% summation successful RT performance. Though it should beryllium noted that AMD’s numbers are with FSR enabled; truthful we cannot divorcement these gains from immoderate changes that amended FSR show connected the 7900 XTX.
Last, but not least, AMD has made an absorbing determination with clockspeeds connected the RDNA 3. In short, AMD has decoupled their clocks; alternatively than moving the full GCD astatine the aforesaid clockspeed, AMD volition beryllium moving the shaders and front-end astatine antithetic clockspeeds. In the lawsuit of the 7900 XTX, this volition spot the shaders moving astatine 2.3GHz (the advertised crippled timepiece speed), portion the front-end volition tally astatine a somewhat speedier 2.5GHz (about 9% faster).

AMD did not spell into large item connected wherefore they’ve made this change, but astatine a precocious level it’s each astir balancing show versus powerfulness consumption. The shaders could tally astatine 2.5GHz arsenic good (indeed, the 7900 XTX’s rated boost timepiece is 2.5GHz), but arsenic we’ve seen clip and clip again, those last clocks are the astir costly successful presumption of powerfulness arsenic you spell up the v/f curve. So AMD has made the prime to springiness up a spot of imaginable show to prevention a batch connected power, arsenic 96 CUs/12288 ALUs is simply a batch of silicon to airy up. Conversely, the front-end is comparatively small, and with AMD having beefed up their CUs by truthful much, spending a spot much powerfulness connected the front-end is presumably worthy it to support them from bottlenecking the remainder of the GPU.
RDNA 3 Display & Media Engines: The Latest and the Greatest
AMD’s halfway compute/graphics architecture was not the lone portion of the RDNA 3 architecture to get an update successful this generation. AMD has besides utilized the accidental to upgrade their show and media engines to enactment caller features and caller formats.
On the show motor front, AMD’s show engine, which they are present calling the “AMD Radiance Display Engine” has been upgraded to enactment DisplayPort 2.1. Specifically, AMD has added enactment for the DisplayPort 2.x diagnostic suite arsenic good arsenic the UHBR 10 and UHBR 13.5 information rates. This means that RDNA 3 cards tin connection 2x the DisplayPort bandwidth of their DisplayPort 1.4-enabled predecessors, which successful crook allows for higher resolutions and higher refresh rates. Notably, this ever truthful somewhat exceeds HDMI 2.1’s bandwidth arsenic well, putting DisplayPort backmost into the lead, astatine slightest connected AMD cards.

Unsurprisingly, AMD is utilizing this functionality to propulsion forthcoming higher solution and higher refresh complaint gaming monitors, including a Samsung ultrawide show acceptable to motorboat successful 2023 with a horizonal 8K resolution. So it’s not conscionable for showing disconnected specs, and AMD and its partners are intending to enactment it to bully use.

AMD has not said thing astir the full fig of supported displays. So astatine this constituent I expect it’s inactive a maximum of 4 displays.
Meanwhile connected the media motor front, AMD has fixed RDNA 3 enactment for the latest and top video codecs. Along with the accustomed H.264 and H.265 support, RDNA 3’s media engines besides adhd afloat AV1 encode and decode support, making this the latest GPU household to rotation retired enactment for the next-generation unfastened format codec. RDNA 3 volition beryllium capable to encode and decode AV1 astatine up to 8Kp60.

The wide show of the media motor has been accrued significantly. According to AMD the media motor runs 80% faster than it did connected RDNA 2 parts, allowing for simultaneous encoding (or decoding) of up to 2 H.264/H.265 streams. Though it’s unclear if that besides applies to AV1.

Finally connected the taxable of AMD’s GPU uncore, portion not explicitly called retired successful AMD’s presentation, it’s worthy noting that AMD has not updated their PCIe controller. So RDNA 3 inactive maxes retired astatine PCIe 4.0 speeds, with Big Navi 3x offering the accustomed 16 lanes. This means that adjacent though AMD’s latest Ryzen level supports PCIe 5.0 for graphics (and different PCIe cards), their video cards won’t beryllium reciprocating successful this generation. In fact, this means that nary 1 volition person a PCIe 5.0 user video card.
Radeon RX 7900 XTX & Radeon RX 7900 XT: Launching December 13th
Bringing today’s uncover afloat circle, let’s crook backmost to the cards themselves, the Radeon RX 7900 XTX and RX 7900 XT.
AMD’s flagship paper volition beryllium the Radeon RX 7900 XTX. While we’re inactive waiting connected confirmation of this, this would look to beryllium a fully-enabled Big Navi 3x part, with each of the blocks successful some the GCDs and the idiosyncratic MCDs themselves enabled. As mentioned previously, AMD is touting a wide show uplift of up to 70% versus the previous-generation flagship, the RX 6950 XT.
Internally, this means 96CUs and 96MB of L3 Infinity Cache volition beryllium disposable connected the card. The crippled timepiece (average clockspeed) volition beryllium 2.3GHz, portion based connected different AMD figures, we tin infer that the boost (maximum) clockspeed volition beryllium 2.5GHz. The crippled timepiece successful peculiar is simply a ~10% betterment implicit the 6950 XT, truthful AMD is enjoying a humble frequence uplift generation-over-generation, but thing excessively massive. Most of the dense lifting volition travel courtesy of the architecture and representation changes.
Speaking of memory, the RX 7900 XTX volition beryllium paired with 24GB of GDDR6 representation moving astatine (at least) 20Gbps. Apparently, AMD’s partners person the headroom to spell adjacent higher than this with mill overclocking, but the level worth for the portion volition beryllium 20Gbps overall. This is simply a humble summation successful representation clockspeeds versus the 6950 XT (11%). Instead, the bulk of the VRAM bandwidth gains volition travel from the 50% larger representation bus, with the 7900 XTX moving to a sizable 384-bit bus. In total, this means the 7900 XTX volition person 960GB/sec of representation bandwidth, 66% much than its predecessor. AMD got their “free” representation subsystem show boost successful the past procreation with Infinity Cache, truthful for this clip around, they are backmost to needing to adhd much carnal representation bandwidth to support the ever-growing beast decently fed.
Meanwhile, the 7900 XT volition beryllium a spot disconnected the block, with less CUs, little VRAM, and little clockspeeds. All told we’re looking astatine 84CUs paired with 20GB of 20Gbps GDDR6, and backed by an 80MB infinity cache. The card’s crippled clockspeed standing is 2.0GHz, and we bash not person immoderate accusation connected the boost clockspeed. The operation of a 13% driblet successful clockspeeds and 13% driblet successful CUs adds up to what is, connected paper, a 24% shortage successful compute/shading performance. That said, AMD’s pricing indicates that the real-world show spread shouldn’t beryllium this high, and we’re inactive missing immoderate important details specified arsenic ROP counts. So for amended oregon worse, we don’t person a bully framework of notation fright present for however the 7900 XT volition execute comparative to thing else, current-generation oregon last.
Unsurprisingly, powerfulness depletion astatine the precocious extremity volition beryllium going up. The 7900 XTX volition beryllium a 355W card, up 20W from the 335W 6950 XT (and 55W from the 300W 6900 XT). This is simply a much humble powerfulness request than connected NVIDIA’s high-end RTX 4090 Ti (450W), but we’re inactive talking astir a paper good northbound of 300W. For gamers with a somewhat smaller appetite for ample powerfulness bills, the 7900 XT volition beryllium holding the enactment astatine 300W. Both cards volition necessitate 2 8-pin PCIe powerfulness connectors.

AMD has besides sent implicit pictures of some the notation 7900 XTX and 7900 XT. Of peculiar note, some cards volition feature, for the archetypal clip for an AMD user card, a USB-C larboard for show outputs. However dissimilar NVIDIA’s earlier task successful this field, this isn’t for VR use, but alternatively for much straight hooking up monitors that trust connected DisplayPort Alt Mode implicit USB-C. Rounding retired the postulation volition beryllium a paid of DisplayPorts (2.1) and an HDMI 2.1 port.
Both cards are utilizing a caller triple instrumentality blower plan from AMD. We’re inactive waiting connected further details here, but AMD has told america that the 7900 XTX measures 287mm long, and is 2.5 slots wide.

Wrapping things up, some cards volition beryllium launching connected December 13th, with AMD readying connected having some notation and AIB partners’ cards connected the support for motorboat day. The 7900 XTX volition commencement astatine $999, meantime the 7900 XT volition beryllium close down it astatine $899. AMD isn’t offering immoderate show comparisons versus NVIDIA cards, but astatine this juncture it seems similar the wildcard is the soon-to-launch GeForce RTX 4080 16GB. By the clip AMD launches successful December, we should person a overmuch amended thought of wherever AMD and NVIDIA’s dueling lineups basal successful examination to each other.

