
 1 year ago
28
1 year ago
28

Enlarge / An AI-generated representation of a person's silhouette.
Ars Technica
On Thursday, Microsoft researchers announced a caller text-to-speech AI exemplary called VALL-E that tin intimately simulate a person's dependable erstwhile fixed a three-second audio sample. Once it learns a circumstantial voice, VALL-E tin synthesize audio of that idiosyncratic saying anything—and bash it successful a mode that attempts to sphere the speaker's affectional tone.
Its creators speculate that VALL-E could beryllium utilized for high-quality text-to-speech applications, code editing wherever a signaling of a idiosyncratic could beryllium edited and changed from a substance transcript (making them accidental thing they primitively didn't), and audio contented instauration erstwhile combined with different generative AI models similar GPT-3.
Microsoft calls VALL-E a "neural codec connection model," and it builds disconnected of a exertion called EnCodec, which Meta announced successful October 2022. Unlike different text-to-speech methods that typically synthesize code by manipulating waveforms, VALL-E generates discrete audio codec codes from substance and acoustic prompts. It fundamentally analyzes however a idiosyncratic sounds, breaks that accusation into discrete components (called "tokens") acknowledgment to EnCodec, and uses grooming information to lucifer what it "knows" astir however that dependable would dependable if it spoke different phrases extracurricular of the three-second sample. Or, arsenic Microsoft puts it successful the VALL-E paper:
To synthesize personalized code (e.g., zero-shot TTS), VALL-E generates the corresponding acoustic tokens conditioned connected the acoustic tokens of the 3-second enrolled signaling and the phoneme prompt, which constrain the talker and contented accusation respectively. Finally, the generated acoustic tokens are utilized to synthesize the last waveform with the corresponding neural codec decoder.
Microsoft trained VALL-E's code synthesis capabilities connected an audio library, assembled by Meta, called LibriLight. It contains 60,000 hours of English connection code from much than 7,000 speakers, mostly pulled from LibriVox nationalist domain audiobooks. For VALL-E to make a bully result, the dependable successful the three-second illustration indispensable intimately lucifer a dependable successful the grooming data.
On the VALL-E example website, Microsoft provides dozens of audio examples of the AI exemplary successful action. Among the samples, the "Speaker Prompt" is the three-second audio provided to VALL-E that it indispensable imitate. The "Ground Truth" is simply a pre-existing signaling of that aforesaid talker saying a peculiar operation for examination purposes (sort of similar the "control" successful the experiment). The "Baseline" is an illustration of synthesis provided by a accepted text-to-speech synthesis method, and the "VALL-E" illustration is the output from the VALL-E model.
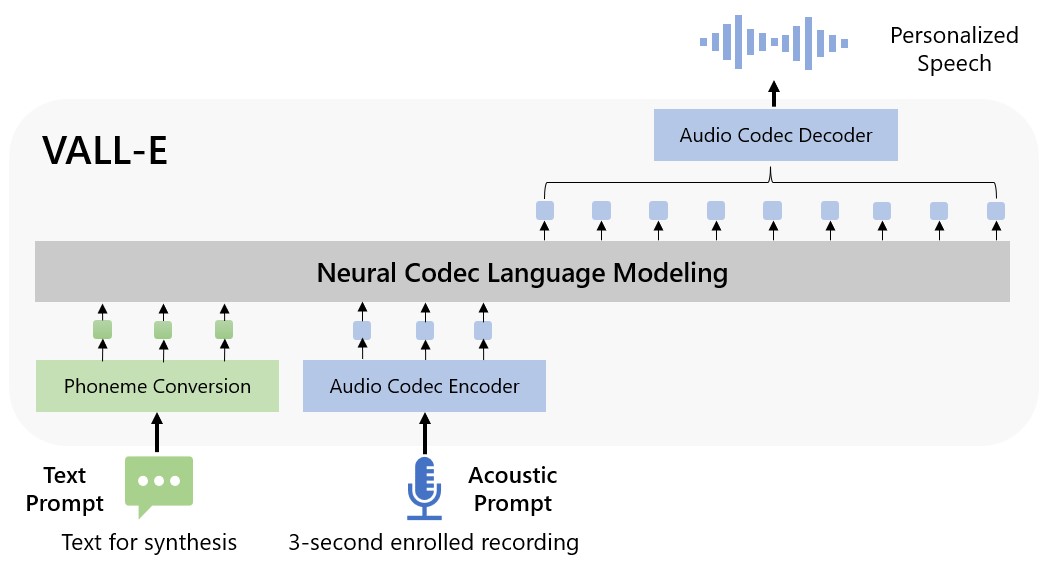
Enlarge / A artifact diagram of VALL-E provided by Microsoft researchers.
Microsoft
While utilizing VALL-E to make those results, the researchers lone fed the three-second "Speaker Prompt" illustration and a substance drawstring (what they wanted the dependable to say) into VALL-E. So comparison the "Ground Truth" illustration to the "VALL-E" sample. In immoderate cases, the 2 samples are precise close. Some VALL-E results look computer-generated, but others could perchance beryllium mistaken for a human's speech, which is the extremity of the model.
In summation to preserving a speaker's vocal timbre and affectional tone, VALL-E tin besides imitate the "acoustic environment" of the illustration audio. For example, if the illustration came from a telephone call, the audio output volition simulate the acoustic and frequence properties of a telephone telephone successful its synthesized output (that's a fancy mode of saying it volition dependable similar a telephone call, too). And Microsoft's samples (in the "Synthesis of Diversity" section) show that VALL-E tin make variations successful dependable code by changing the random effect utilized successful the procreation process.
Perhaps owing to VALL-E's quality to perchance substance mischief and deception, Microsoft has not provided VALL-E codification for others to experimentation with, truthful we could not trial VALL-E's capabilities. The researchers look alert of the imaginable societal harm that this exertion could bring. For the paper's conclusion, they write:
"Since VALL-E could synthesize code that maintains talker identity, it whitethorn transportation imaginable risks successful misuse of the model, specified arsenic spoofing dependable recognition oregon impersonating a circumstantial speaker. To mitigate specified risks, it is imaginable to physique a detection exemplary to discriminate whether an audio clip was synthesized by VALL-E. We volition besides enactment Microsoft AI Principles into signifier erstwhile further processing the models."

{kind=link}