URL parameters or query strings are the part of a URL that typically comes after a question mark (?) and are used to pass data along with the URL. They can be active parameters that modify page content or passive parameters that are mostly used for tracking and do not change the content. They are made up of key-value pairs, where the key tells you what data is being passed and the value is the data you’re passing, such as an identifier. They look like ?key=value but may be separated by ampersands (&) like ?key=value&key2=value2 if there is more than one pair. In this guide, we’ll be covering what you need to know about URL parameters. As I mentioned in the intro, parameters can be active or passive. Let’s look at some examples of each. Active parameters modify the content of the page in some way. Filter. Removes some of the content, leaving more specific content on the page that a user wants to see. An example of this is faceted navigation in e-commerce. ?color=yellow Sort. Reorders the content in some way, such as by price or rating. ?sort=highest_rated Paginate. Divides content into a series of related pages. ?p=2 Translate. Changes the language of the content. ?lang=de Search. Queries a website for information that a user is looking for. On our search engine, yep.com, we use the key “q” for the query, and the value contains info about the user query. ?q=ahrefs Passive parameters do not change the content. They are typically used for tracking. Let’s look at some examples of each. Affiliate IDs. Passes an identifier used to track where sales and signups come from. ?id=ahrefs Advertising tags. Tracks advertising campaigns. ?utm_source=newsletter Session IDs. Identifies a particular user. It’s not common on modern websites to use session IDs to track users. ?sessionid=12345 Video timestamps. Jumps to the designated timestamp in a video. ?t=135 URL parameters can cause a number of different issues when it comes to SEO, especially in cases where multiple parameters are used. Here are some of the problems you may encounter. Passive parameters can cause issues with duplicate content. Typically, you want them to be crawled, and each page should have a canonical set to the main version. There may be times where you want to block these parameters from being crawled completely using robots.txt—but only in situations where you may have issues with crawl budget. We’ll cover this more later. Google will choose a version of the page to index in a process called canonicalization, and signals such as links will consolidate to that indexed version. Active parameters may create pages with near-duplicate content or content that is very similar to other content. They may also be completely different content. You’ll need to check what your parameters are actually used for. You should avoid passive parameters like those used for tracking on internal links (links from one page on your site to another). This is still an all-too-common practice on larger sites, but I want to emphasize that this is an old and outdated practice that you should not be doing. Most analytics systems have event tracking you can use instead that still records the data without adding parameters to your URLs. It’s fine to use active parameters on internal links in most cases. Infinite URL paths with parameters or tons of different combinations can cause issues with crawling. Keep a consistent order, and don’t have paths that allow for adding additional parameters. You can easily find potentially infinite paths using the Depth report under the Structure Explorer tool in Site Audit. It’s not common for websites to have 9+ levels, so this is a strong indicator that there may, in fact, be infinite paths or some other issue. Google will make adjustments as it recognizes infinite paths or certain patterns when crawling. It will try to limit the crawling of URLs that it thinks won’t be useful or are repetitive. URL parameters are sometimes used for international websites. These are listed as an option for locale-specific URLs. But even Google says it’s not recommended. It adds another layer of complexity where more things can go wrong. You also won’t be able to geo-target these URLs in Google Search Console. Parameters are commonly used in e-commerce for everything—from tracking, to pagination, to faceted navigation. These topics can be pretty complex, so I recommend reading through the blog posts I linked to better understand them. There’s a growing trend where people are using # instead of ? as the fragment identifier, especially for passive parameters like those used for tracking. This is generally not a good idea. But in specific cases, it may be OK to do this to replace unnecessary parameters. I tend to recommend against it because of all of the issues. The problem is anything after a # is ignored by servers, and a lot of systems simply will not or cannot recognize parameters using a #. Additionally, # already has a designated use case, which is to scroll to a part of the page. This is done on the client side, and JavaScript devs may also use it for “routing” to a page with different content. It’s a good idea to check what parameters are used on your site. In Site Audit’s Page Explorer tool, you can search for URLs that contain a question mark (?). You can use the advanced filters to find pages with multiple parameters or to start excluding parameters to help you identify all the various parameters used on your website. Once you know what parameters are used, I recommend checking a few of the pages to see what the parameters actually do. You can also check the Duplicates report for exact or near-duplicates. The visual makes it easy to see if you have a lot of versions of the same or similar pages and whether or not they have matching canonical tags to choose a preferred version. You can click into each cluster to get more information. There’s also an option under “Bulk export” that lets you export all of the duplicate content at once. I find this option easier to use for larger sets of data. In the past, Google had a URL parameter tool in Google Search Console where you could choose how to treat different parameters based on whether or not it changed the page content. The tool was deprecated in early 2022. Here’s what Google had to say about it: When the URL Parameters tool launched in 2009 in Search Console’s predecessor, Webmaster Tools, the internet was a much wilder place than it is today. SessionID parameters were very common, CMSes had trouble organizing parameters, and browsers often broke links. With the URL Parameters tool, site owners had granular control over how Google crawled their site by specifying how certain parameters affect the content on their site. Over the years, Google became much better at guessing which parameters are useful on a site and which are —plainly put— useless. In fact, only about 1% of the parameter configurations currently specified in the URL Parameters tool are useful for crawling. Due to the low value of the tool both for Google and Search Console users, we’re deprecating the URL Parameters tool in 1 month. While not mentioned, I suspect that some users might have been hurting themselves with the tool. I ran into this in the past where someone put in a wrong setting that said the content did not change, but it did. This knocked a few hundred thousand pages out of the index for that site. Whoops! You can let Google crawl and figure out how to handle the parameters for you, but you also have some controls you can leverage. Let’s look at your options. A canonical tag can help consolidate signals to a chosen URL but requires each additional version of a page to be crawled. As I mentioned earlier, Google may make adjustments as it recognizes patterns, and these canonicalized URLs may be crawled less over time. This is what I’d opt for by default. But if a site has a ton of issues and parameters are out of control, I may look at some of the other options. A noindex meta robots tag removes a page from the index. This requires a page to be crawled. But again, it may be crawled less over time. If you need signals to consolidate to other pages, I’ll avoid using noindex. Blocking parameters in robots.txt means that the pages may still get indexed. They’re not likely to show in normal searches. The problem is that these pages won’t be crawled and won’t consolidate signals. If you want to consolidate signals, avoid blocking the parameters. When setting up a project in Site Audit, there’s a toggle in the crawl settings called “Remove URL Parameters” that you can use to ignore any URLs with parameters. You can also exclude parameterized URLs in the crawl setup using pattern matching. Sidenote. Fun fact: We only count the canonicalized version of pages toward your crawl credits. Just to summarize, URL parameters have a lot of different use cases, and they may or may not cause issues for your site. Everything is situational. Message me on Twitter if you have any questions.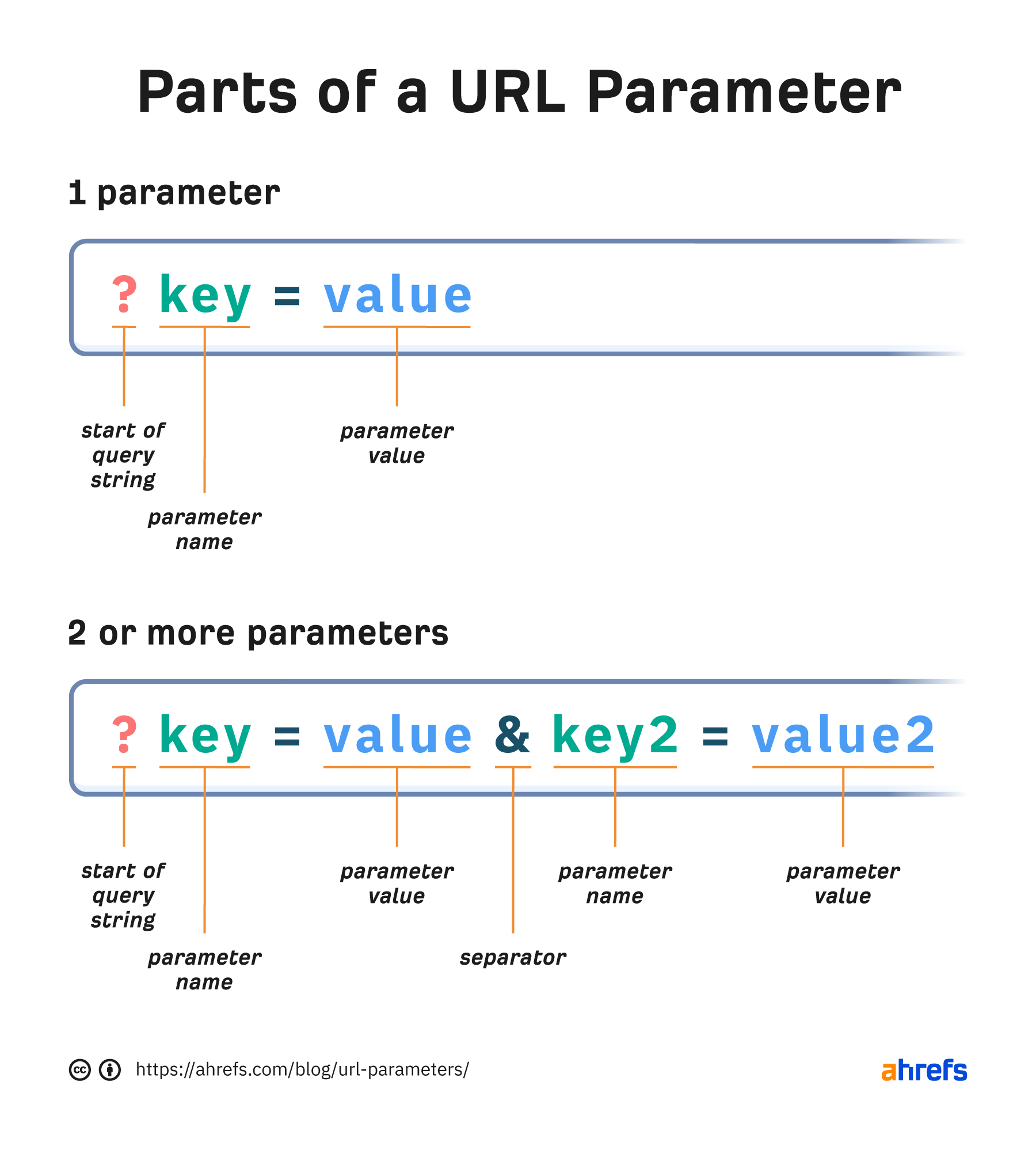 Explanation of URL parameter parts.
Explanation of URL parameter parts.Active parameters
Passive parameters
Internal links
Crawling
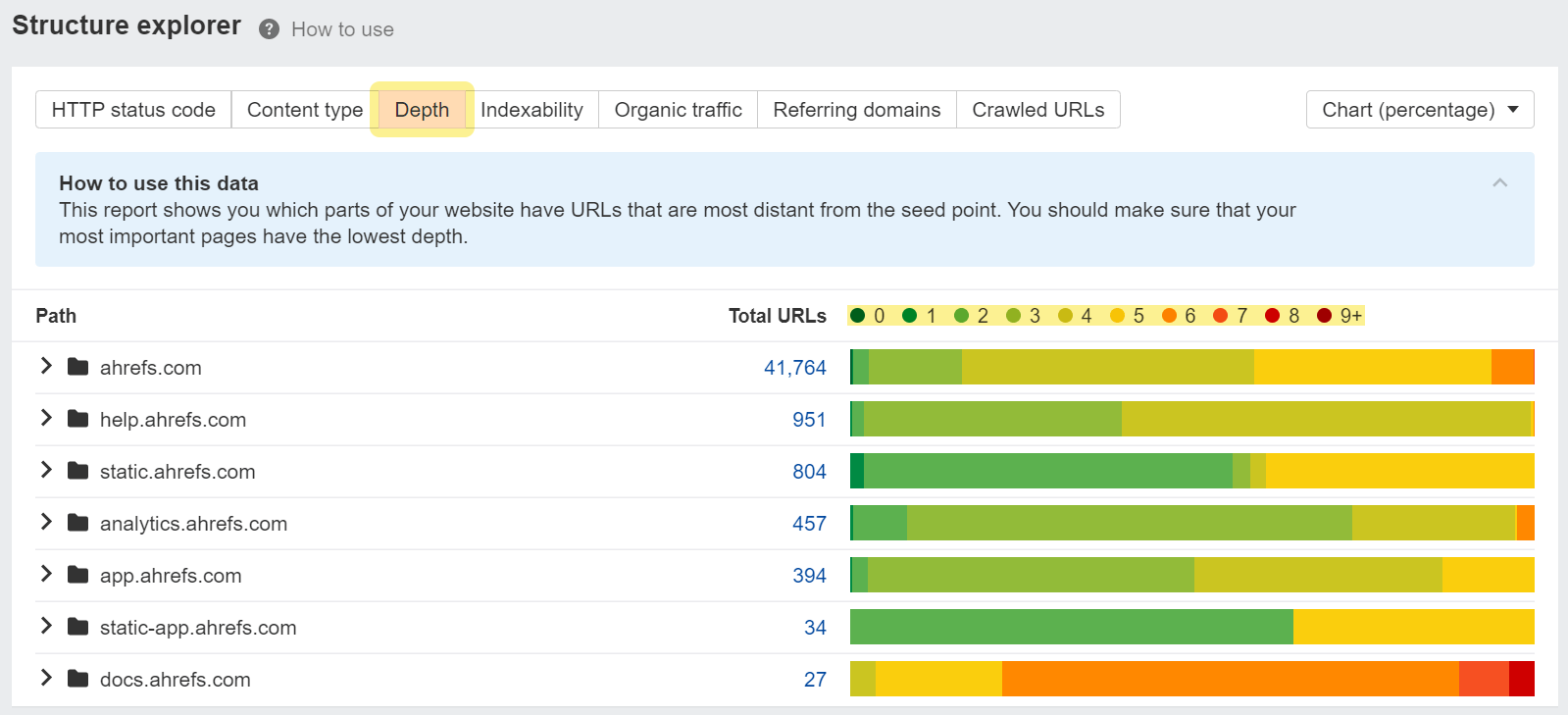 Depth report in Structure Explorer.
Depth report in Structure Explorer.Internationalization
E-commerce
JavaScript
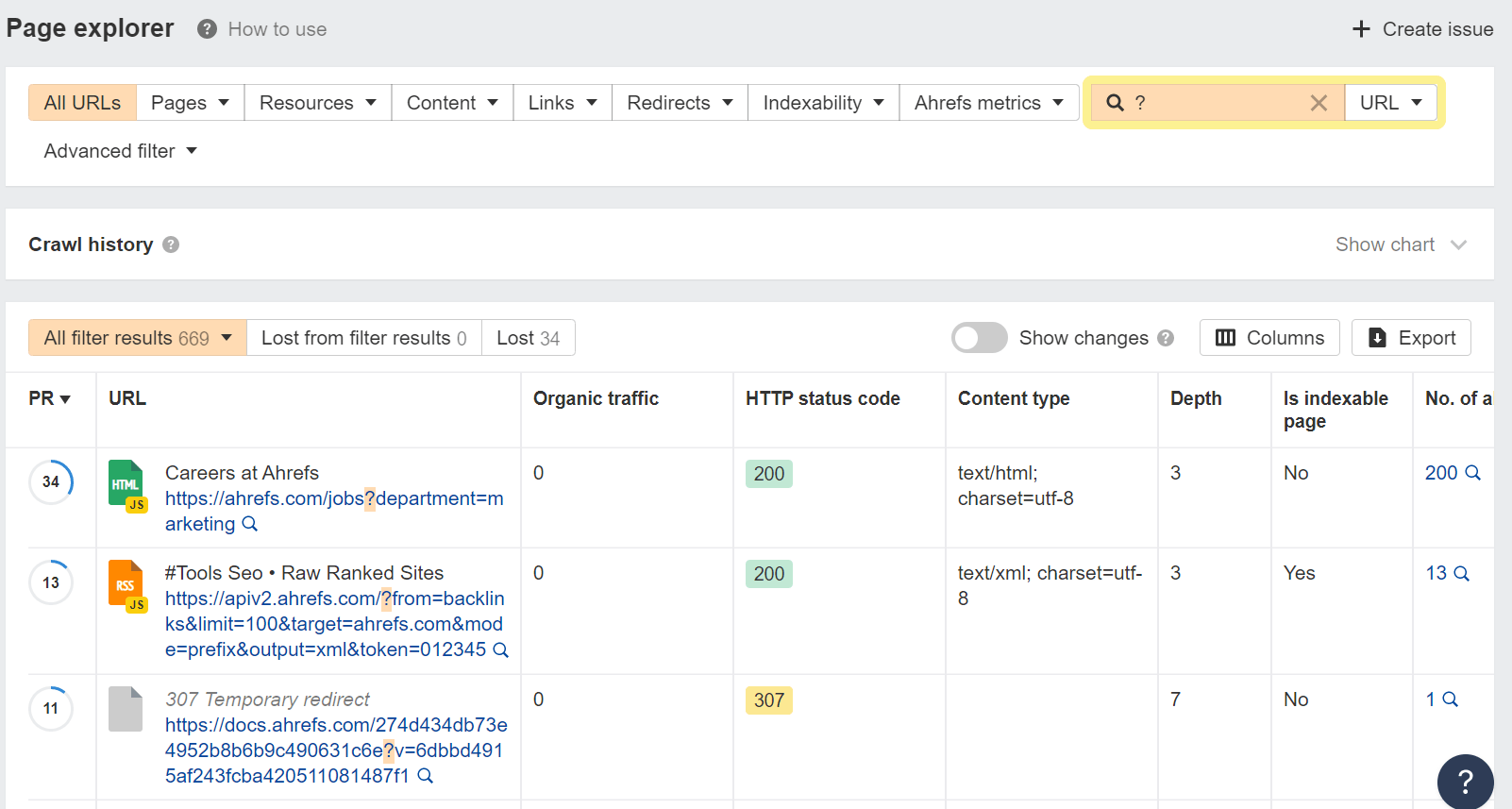 Searching for parameters in Page Explorer.
Searching for parameters in Page Explorer. Duplicate content tree map view to show clusters.
Duplicate content tree map view to show clusters.Canonical tags
Noindex
Blocking in robots.txt
Site Audit
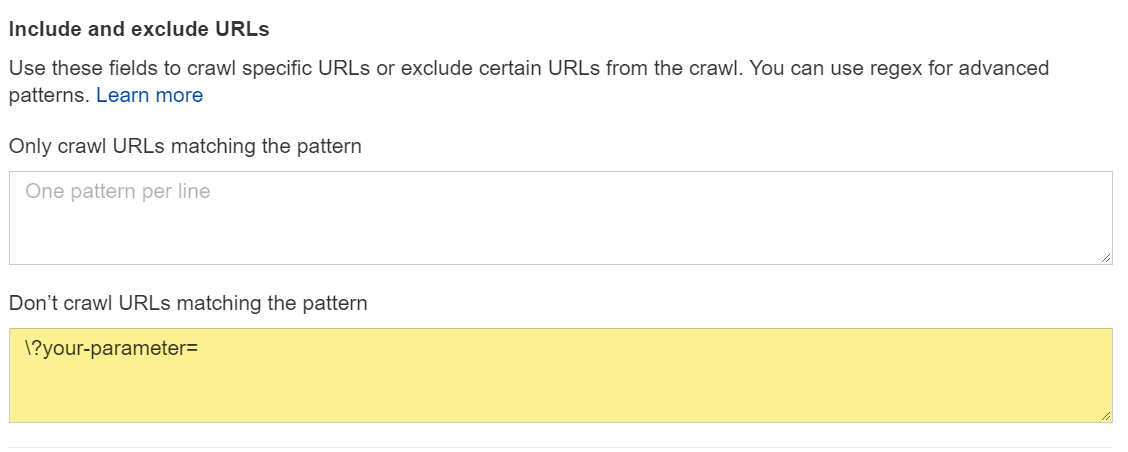 Blocking a parameter in Site Audit.
Blocking a parameter in Site Audit.Final thoughts
URL Parameters: A Complete Guide for SEOs
 2 years ago
151
2 years ago
151
Related

5 Smart Ways to Spy On Your Competitors’ Ads
4 hours ago
0


GEO, LLMO, AEO… It’s All Just SEO
1 day ago
2